
CS294-2 Grouping and Recognition
November 8, 1999
Scribe Notes by Greg Mori
There are 3 ways to attack the problem of shape equivalence:
The steps to this method of determining shape equivalence are:
In order to compare the two groups of points (or features) above, we first must choose a frame with which to come up with the proposed transformation. A frame is a set of points used to come up with the transformation (the hypothesis that will be tested).
The idea is to guess a correspondence of points, eg. (A,B) -> (1,2), construct the transformation T that takes A->1 and B->2, then to apply that transformation to the other points C and D. We then check to see that whether or not there are points in the second group that are close to T(C) and T(D). If so, then the two groups of points are deemed to be similar.
In order to account for noise in the measurement of the points, we can use more points in formulating the hypothesis transformation and allow some leeway in the measurement of "close" between each T(x) and points in the second group.
In the name Pose Consistency Algorithm, "pose" refers to the transformation. It is "consistent" because all points are subjected to the same transformation (also called "viewpoint consistency").
Ex. T is a 2D Euclidean transform.
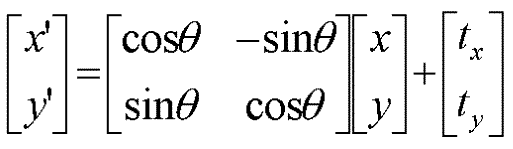
Two pairs of points are needed to come up with a transformation. If there are
n points in group 1 and n points in group 2, there are ![]() total
correspondences between points in the two groups. For each of these correspondences
the transformation must be computed, and then each point in group 1 must be
transformed and checked against points in group 2. Using a Voronoi diagram for
testing against the points in group 2, this gives us
total
correspondences between points in the two groups. For each of these correspondences
the transformation must be computed, and then each point in group 1 must be
transformed and checked against points in group 2. Using a Voronoi diagram for
testing against the points in group 2, this gives us ![]() complexity.
complexity.
Ex. T is a 3D Euclidean transform followed by a projection.
This is more difficult than the straight 2D Euclidean transformation. There are 6 unknowns in the transformation: 3 for rotation, 3 for translation. By counting equations, we can observe that at least 3 points are needed to define the transformation (in fact, 3 points are sufficeint). See Huttenlocher and Ullman for how to obtain the transformation in this case.
![]()
It is important to note that in this case n is not necessarily equal to m. There are a number of reasons why they could be different:
We will need to take this inequality into account when defining when it is that a group of translated points is similar to a group of points in the image.
In this example there are ![]() total correspondences. Again, for each of these correspondences we must compute
the hypothesized translation, then test (m-3) points in the Voronoi diagram
of points in group 2. So the complexity is
total correspondences. Again, for each of these correspondences we must compute
the hypothesized translation, then test (m-3) points in the Voronoi diagram
of points in group 2. So the complexity is ![]() ,
which is
,
which is ![]() .
This seems daunting at the outset, but there are tricks to make this complexity
on the order of n^3 or so.
.
This seems daunting at the outset, but there are tricks to make this complexity
on the order of n^3 or so.
We can reduce the complexity by using two points, each on its own line (edge
in object space), instead of 3 points to come up with the transformation. It
is still possible to construct the transformation because we can define a third
ficticious point at the intersection of the two lines (assume not parallel).
Now we only need to enumerate over all possible pairs, instead of triplets.
This means we only have ![]() correspondences.
correspondences.
There are many different classes of transforms that can be used. Below is a table that lists transformation classes and the number of point pair correspondences needed to determine a transformation of each class.
| Transformation | # of points needed for frame |
| 2D Euclidean | 2 |
| 3D Euclidean |
3 |
| 2D Affine | 3 |
| 3D Affine | 4 |
| 3D Affine, followed by projection | 4 |
|
3D Euclidean, followed by projection |
3 |
In general, the Pose Consistency method works well when objects have features that are easy to identify. For example, objects with sharp corners or chemical structures. However, this method does not work well on curved objects, or any object that lacks recognizable features to use as points of comparison.
This method of comparing shapes is mathematically equivalent to the Pose Consistency Algorithm described above. The difference is only a computational one -- the actual transformation is never explicitly computed. As in the above algorithm, we first choose a frame in which to operate. We then measure the coordinates of the remaining points in both coordinate systems, and compare.
Ex. 2D Euclidean
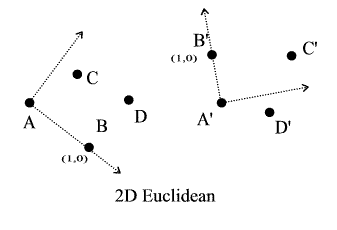
In this example (A,B)
is the frame. We express the points C and D in the coordinate system defined
by this frame, and compare to C' and D'.
Ex. 2D Affine
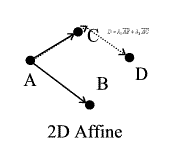
In this example (A,B,C)
define the frame. Under affine transformations, angles aren't necessarily preserved.
Instead, we express D as a combination of the vectors AB and AC.
How is this used for recognition?
Geometric Hashing (Landon, Schwartz, and Wolfson) has two phases:
Offline
In the offline phase, for each frame we compute affine (or Euclidean) coordinates
for all the points in the object. We store these in a quantized hash table.
Each element in the table is <model name, frame points>. There is one
common table into which all object types being considered are hashed. Note that
there will likely be multiple entries into the same bucket in this hash table.
The recognition process is sensitive to the selection of a good quantization.
Online
In the online recognition phase as usual we run through all possible frames.
For each choice of a frame, we compute affine coordinates for the remaining
image points in that frame. We look up these computed coordinates in the hash
table, and note the entries in that bucket. Each entry <model name,
frame points> counts as one "vote" for the unknown image
being a picture of model from frame. After running through all
sets of points from the image, we determine the image to be one of the model
with the highest number of votes. The complexity of this algorithm is better
since we do much of the processing offline. There are only ![]() online coordinate computations and hash table lookups in the 2D affine case.
online coordinate computations and hash table lookups in the 2D affine case.