


791 matches 247 matches 16 matches
But if you have enough detail for Query 3, then you practically have the queried image already and that is not terribly helpful.
Two main applications of practical image recognition are:
Currently, the best way we have to do this is through the Internet, using a search engine such as Altavista. Altavista is not generally too successful at image retrieval since it tries to find a keyword similar to the queried image (e.g. searching captions).
How can we improve this?
Rough sketch of process:
Recommended site: www.thinker.edu
This is the Legion of Honor museum in SF. Look for the "Image
Base"
With this many images in so many databases, how can you find what you want?
One solution is to add text to the pictures (i.e. use a set of descriptive terms or phrases to represent each image). There are two problems with this solution. First, such a method could not be completely exhaustive, and any attempt would become far to unwieldy or impractical very quickly.
For example, a Van Gogh painting. How could you describe it so that someone else could query it?
Luckily, there are patterns and trends in how and what people query for, such as

Icon1 Icon2 Icon3
791 matches
247 matches
16 matches
But if you have enough detail for Query 3, then you practically have
the queried image already and that is not terribly helpful.
Histogram Matching (wavelets)
Blobs
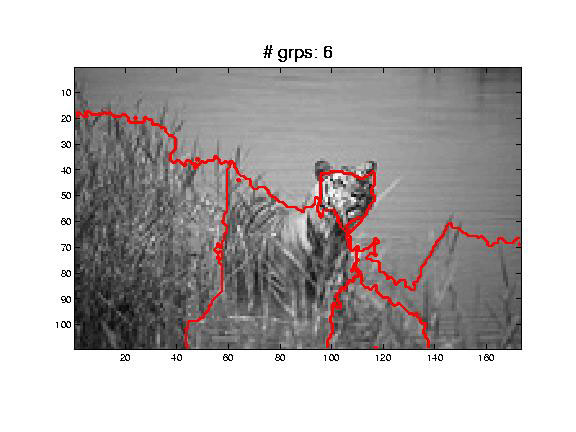
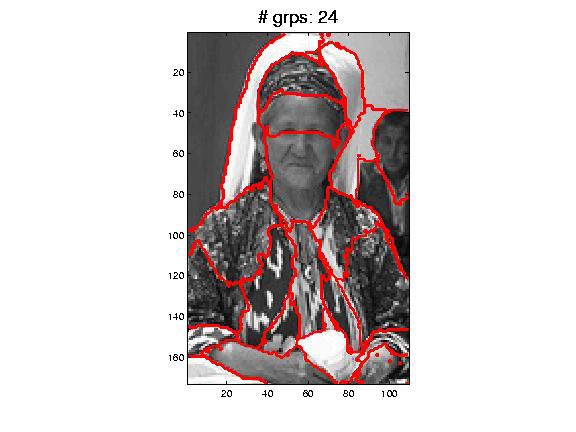
BAD RESULTS
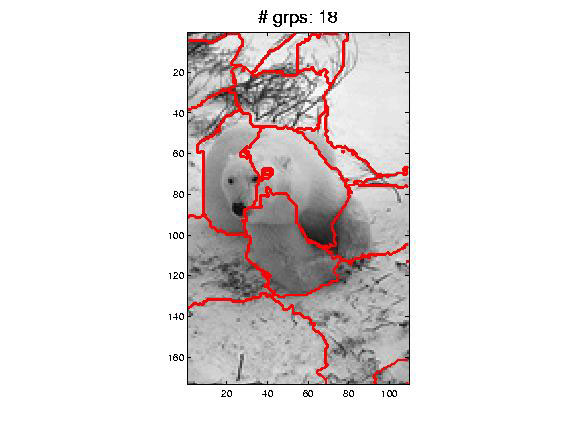

Why this mixed bag of errors?
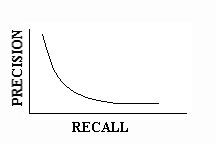
The relationship between precision and recall
Object recognition is also application dependent. What do you intend to do with the image and what kinds of images are you looking at.
What about real tasks? What causes the errors you see?
While you do get better recognition and better segmentation with normalized cuts, it is hard to ignore spurious boundaries (see examples).
What about color? These are all black and white images, if they were in color, it would be easier to segment certain areas.
What about focus? With less focus, high frequency texture
information gets lost.
End Scribe Notes
Prof. Malik will continue Wed with the biological object recognition (cortical locality of image processing and neural processes) part of this lecture.
Announcements: