
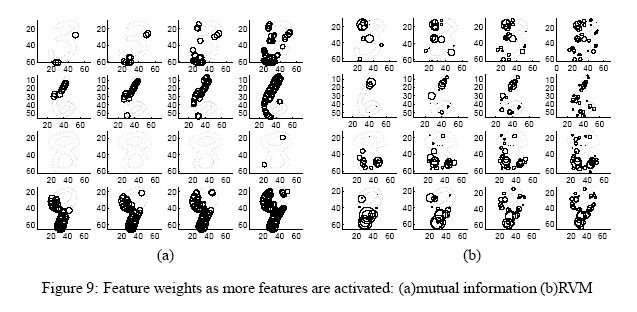
Details/Abstract: The task of visual object recognition benefits from feature selection as it reduces the amount of computation in recognizing a new instance of an object, and the selected features give insights into the classification process. We focus on a class of current feature selection methods known as embedded methods: due to the nature of multi-way classification in object recognition, we derive an extension of the Relevance Vector Machine technique to multi-class. In experiments, we apply Relevance Vector Machine on the problem of digit classification and study its effects. Experimental results show that our classifier enhances accuracy, yields good interpretation for the selected subset of features and costs only a constant factor of the baseline classifier.
Publication: Hao Zhang, Jitendra Malik. Selecting shape features using multi-class relevance vector machine. Technical Report UCB/EECS-2005-6, EECS Department, University of California, Berkeley, October 10 2005.
Graphical model of the classifier multiclass- RVM


We try to capture in a still image the movement of an object over time.
Details/Abstract:
We introduce a new method to describe, in a single image, shape
relationships over time. We acquire both range and image information
in a sequence of frames using a stationary stereo camera. From the
pictures taken, we compute a composite image consisting of the image
pixels from the surface closest to the camera over all time frames.
This composite reveals 3-\uppercase{d} relationships between the shapes at
different times, displayed by occlusion cues in the composite
image. We call the composite a shape-time photograph.
Small errors in stereo depth measurements can create artifacts in the shape-time images. We correct most of these using a Markov network to estimate, at each pixel, the most probable time-frame showing the front-most surface, taking into account (a) the stereo depth measurements and their uncertainties, and (b) spatial continuity assumptions for the front-surface time-frame assignments.
Links:
Publication: Bill Freeman, Hao Zhang. Shapetime photography, IEEE Computer Vision and Pattern Recognition, 2003. [PDF]

We try to classify object classes using as much information as we can from shape descriptors (e.g. shape context).
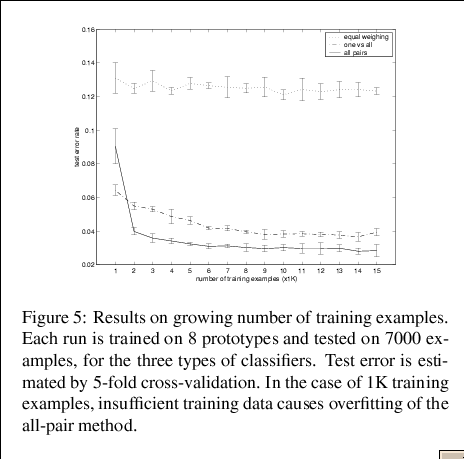
Details: For purpose of object recognition, we learn one discriminative classifier based on one prototype, using shape context distances as the feature vector. From multiple prototypes, the outputs of the classifiers are combined using the method called ``error correcting output codes''. The overall classifier is tested on benchmark dataset (MNIST) and is shown to outperform existing methods with far fewer prototypes.
links:
Publication: Hao Zhang, Jitendra Malik. Learning a discriminative classifier using shape context distances, IEEE Computer Vision and Pattern Recognition, 2003. [PDF]